CorpusRenom



Présentation du corpus
Le corpus a été créé dans le cadre du projet Renom, financé par la région Centre-Val de Loire. Les résultats des travaux réalisés dans le cadre de ce projet sont illustrés par le site Renom.À partir de transcriptions réalisées sur les exemplaires originaux de l’époque (graphies non modernisées), issues du corpus de textes de la Renaissance BVH-Epistemon, les entités nommées ont été pour la plupart repérées par l’outil CasSys d'Unitex avec une cascade de transducteurs développée spécifiquement par le Lifat (Laboratoire d'informatique fondamentale et appliquée). Les textes ont ensuite été relus et corrigés par l'équipe des BVH (Bibliothèques virtuelles humanistes) du CESR (Centre d'Études Supérieures de la Renaissance).
Le corpus est disponible sous la licence Creative Commons CC-BY-NC-SA.
Il est composé des ouvrages suivants :
- François Rabelais
- Gargantua princeps, 1534 (BVH-Epistemon | Renom | PDF | XML-TEI)
- Le Disciple de Pantagruel, 1538 (BVH-Epistemon | Renom | PDF | XML-TEI)
- Gargantua, 1542 (BVH-Epistemon | Renom | PDF | XML-TEI)
- Pantagruel, 1542 (BVH-Epistemon | Renom | PDF | XML-TEI)
- La Sciomachie et festins faits à Rome, 1549 (BVH-Epistemon | Renom | PDF | XML-TEI)
- Le Tiers Livre, 1552 (BVH-Epistemon | Renom | PDF | XML-TEI)
- L'Isle Sonnante, 1562 (BVH-Epistemon | Renom | PDF | XML-TEI)
- Cinquiesme livre, 1564 (BVH-Epistemon | Renom | PDF | XML-TEI)
Présentation de l'annotation
Les éléments de cette annotation ont été choisis parmi ceux proposés par la Text Encoding Initiative (TEI P5). Les textes du corpus sont annotés au niveau des entités nommées par les balises :
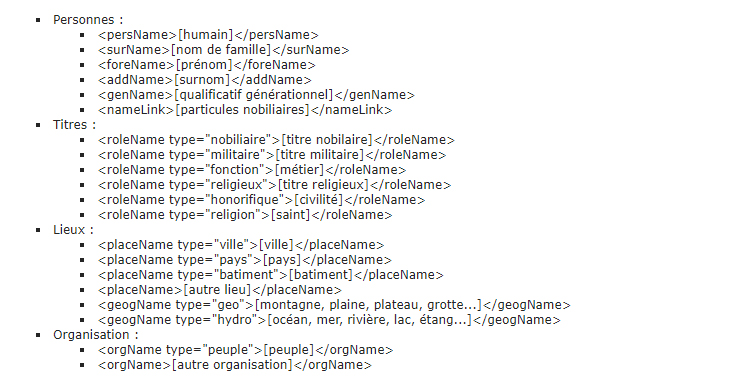
Remarque importante : Le balisage ne concerne pas uniquement les entités nommées, mais aussi l'ensemble de la structure originale du document (lignes, pages, corrections, lettrines, etc.). La documentation complète de ces balises, rédigée par l'équipe BVH, est disponible.
Exemples de balisage

Partenaires du projet
- Lifat : Denis MAUREL et Nathalie FRIBURGER.
- CESR-BVH : Marie-Luce DEMONET, Jorge FINS, Marie OLIVRON, Sandrine BREUIL et Toshinori UETANI.
- LLL : Iris ESHKOL.
Références
- Sur le projet Renom, côté BVH :
- Lay M.-H., Demonet M.-L. (2008). Some elements of reflection about sustainability and shareability of the Humanist Virtual Library (Bibliothèques Virtuelles Humanistes, BVH): a synthesis and experiment feed-back. Workshop Sustainability of Language Resources and Tools for Natural Language Processing. LREC (6th Language Resources and Evaluation Conference). Marrakech.
- Demonet M.-L. (2010). Text retrieval for the BVH Project (Virtual Humanistic Libraries in Tours) : OCR and text processing. The fifth annual Chicago Colloquium on Digital Humanities and Computer Science (DHCS). Northwestern University. Chicago.
- Demonet M.-L., Bertrand L. (2014). Le corpus Epistemon des BVH : l’encodage XML/TEI [Rabelais, Montaigne]. Université Paris IV, séminaire de linguistique.
- Sur le projet Renom, côté Tal :
- Maurel D., Friburger N., Eshkol-Taravella I. (2014). Enrichment of Renaissance texts with proper names. Infotheca, Journal for Digital Humanities, 15:1
- Maurel D., Friburger N., Eshkol-Taravella I. (2017). Tourisme culturel sur Internet : Les noms propres des éditions originales de Rabelais. Zotti V., Pano Alamán A. (dir.), Informatica umanistica: risorse e strumenti per lo studio del lessico dei beni culturali. Firenze University Press. 47-66.
- Sur les cascades de transducteurs :
- Friburger N., Maurel D. (2004). Finite-state transducer cascade to extract named entities in texts. Theoretical Computer Science. 313:94-104.
- Maurel D., Friburger N., Antoine J.-Y., Eshkol-Taravella I., Nouvel D. (2011). Cascades de transducteurs autour de la reconnaissance des entités nommées. Traitement automatique des langues, 52(1):69-96.
Nature des données
Corpus annoté, œuvres originales.
Origine des données
- Fac-similés numériques des éditions originales : Bibliothèque nationale de France, Bibliothèque municipale de Tours, Bibliothèque du CESR.
- Données textuelles : transcription et encodage en XML-TEI : CESR, équipe BVH (Marie-Luce Demonet).
Fiche technique
Version 1.1
Conception : Denis MAUREL, Marie-Luce DEMONET, Jorge FINS, Toshinori UETANI, Sandrine BREUIL, Marie OLIVRON
Format : XML-TEI
Codage des caractères : utf-8 (sans BOM)
Conception : Denis MAUREL, Marie-Luce DEMONET, Jorge FINS, Toshinori UETANI, Sandrine BREUIL, Marie OLIVRON
Format : XML-TEI
Codage des caractères : utf-8 (sans BOM)